
데이터 왜곡 줄이고 본질적 속성만 학습 구현
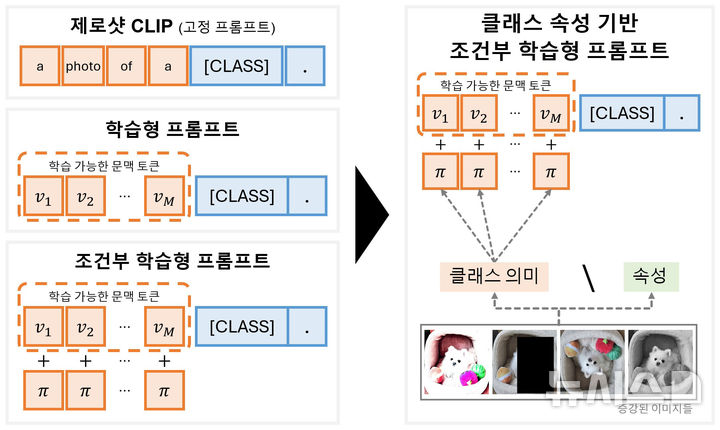
기존의 방식은 '강아지'라는 클래스 정보만 학습했지만, 제안된 기법은 귀, 눈, 털 등 강아지의 공통된 속성을 함께 학습한다. 이를 통해 강아지의 종류나 배경이 달라져도, 모델이 본질적인 속성을 인식해 도메인이 다른 데이터에서도 안정적인 성능을 유지한다. (그래픽=켄텍 제공) [email protected] *재판매 및 DB 금지
[나주=뉴시스]이창우 기자 = 한국에너지공과대학교(KENTECH·켄텍)가 비전-언어 모델(Vision-Language Model, VLM)의 속성 인식 능력을 한 단계 끌어올리는 프롬프트 학습 기술을 선보였다.
켄텍은 이석주 교수 연구팀이 데이터 다양화 과정에서 발생하는 시각적 왜곡 문제를 분석하고, 모델(Vision-Language Model.VLM)이 이미지의 본질적인 속성(attribute)에 집중해 학습하도록 설계한 새로운 프롬프트 학습 기법을 개발했다고 13일 밝혔다.
CLIP 등 기존의 비전-언어 모델은 이미지와 텍스트를 결합해 사물의 의미를 이해할 수 있지만, 세밀한 속성 구분이 필요한 상황에서는 한계가 있었다.
연구팀은 이러한 문제 해결을 위해 '델타 메타 토큰(Delta Meta Token)'을 도입했다.
이 토큰은 이미지 간 상대적 변화를 학습해 세밀한 속성 차이를 구분하도록 돕는 역할을 한다. 이를 통해 모델은 배경이나 조명, 촬영 조건 등 비본질적 요인에 덜 민감해지면서도 대상의 의미 있는 속성을 정교하게 학습할 수 있다.
예를 들어 기존 방식은 '강아지'라는 클래스 정보만 학습했지만, 제안된 기법은 귀, 눈, 털 등 강아지의 공통된 속성을 함께 학습한다.
이를 통해 강아지의 종류나 배경이 달라져도 본질적인 속성을 인식해 도메인이 다른 데이터에서도 안정적인 성능을 유지한다.
이 교수팀의 기법은 사전 학습된 CLIP 모델에 최소한의 파라미터만 추가하는 경량 구조임에도, 11개 벤치마크 데이터셋에서 기존 프롬프트 학습 방식보다 우수한 일반화 성능을 보였다.
특히 새로운 클래스나 도메인이 주어져도 일관된 인식 성능을 유지해, 자율주행·로봇 비전·산업 영상 이상 검출 등 속성 기반 시각 인식이 필요한 분야에 폭넓게 활용될 전망이다.
공동 제1저자인 김가현 연구원은 "켄텍의 자율적이고 협력적인 연구 문화가 새로운 아이디어를 실험하는 데 큰 도움이 됐다"며 "향후 AI 에이전트 협업 연구를 통해 자율형 지능 로봇의 확장 가능성을 탐구할 계획"이라고 말했다.
이번 연구는 산업통상자원부와 한국연구재단의 지원을 받아 수행했다. 연구 결과는 컴퓨터 비전·기계 학습 분야의 국제 저명 학술지 Pattern Recognition (Elsevier) 온라인판에 지난달 23일 게재됐다.
◎공감언론 뉴시스 [email protected]



