
KOSTAT-Did 서비스 시작…마이크로데이터 개인정보 노출 자동 방지
KOSTAT-Did 화면(사진 : 통계청 제공) *재판매 및 DB 금지
[세종=뉴시스] 안호균 기자 = 국가 통계 작성 기관들이 마이크로데이터를 외부에 제공할 때 자동으로 개인정보 노출 위험을 막아주는 프로그램이 보급된다.
통계청은 통계자료(마이크로데이터)의 개인정보 노출 위험을 평가하고 특정 개인·사업체를 식별할 수 없도록 처리하는 프로그램인 'KOSTAT-Did(De-identification)'를 개발, 국가통계작성기관을 대상으로 서비스한다고 4일 밝혔다.
최근 인공지능 대전환(AX) 시대를 맞아 인공지능 학습용 데이터 개방 등 개인·사업체 단위의 상세 자료제공 요구가 증가하고 있다.
그러나 국가통계작성 기관들은 마이크로데이터 전면 개방의 가장 큰 장애 요인으로 개인정보 노출 위험을 꼽고 있다. 제공되는 자료가 상세해질수록 정보의 유용성은 높아지지만 개인정보 노출 위험도 함께 증가하기 때문이다.
통계청은 2023년 '통계작성 및 통계자료 제공을 위한 비식별화 가이드라인'을 배포해 개인 및 단체 기밀 보호와 통계적 유용성 간 균형을 권고한 데 이어, 지난해에는 담당자들이 수작업으로 처리해 온 비식별화 업무를 지원하기 위해 엑셀 기반의 자동 프로그램인 KOSTAT-Did를 개발했다.
이후 외부 기관 실무자와 전문가의 테스트를 거쳐 최종 프로그램을 확정했다. 이날부터 통계정책관리시스템(www.narastat.kr/pms/index.do)을 통해 제공한다. 10월부터는 국가통계작성 기관을 대상으로 맞춤형 사용자 교육도 실시할 예정이다.
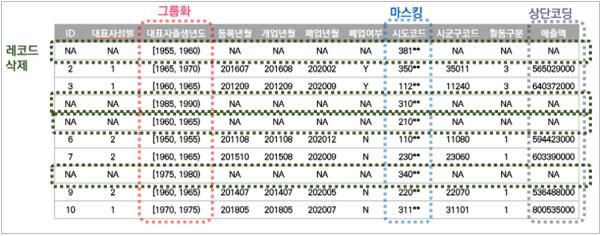
KOSTAT-Did는 통계자료의 특성을 고려해 마스킹, 범주화, 통계적 잡음(노이즈)첨가, 자료교환(스와핑) 등 15종의 비식별화 기법을 지원한다.
마스킹은 '김○○'와 같이 기호를 사용해 개인정보 일부를 가리는 방식이다. 범주화는 수치 등을 표시할 때 개체가 식별될 위험이 있는 경우 보다 큰 범주의 값으로 대체하는 방식이다. 예를 들어 초고령자 연령을 '102세'에서 '100세 이상'으로 범주화하는 식이다.
프로그램상에서 마이크로데이터의 비식별화 처리가 완료되면 표준화된 평가 보고서가 자동 생성된다. 처리 전후의 정보손실도 및 노출위험도를 시각화된 그래프와 정량화된 지표로 비교할 수 있다는 특징이 있다.
이를 통해 통계 담당자는 통계자료의 객관적인 정보보호 수준을 측정·평가할 수 있다. 기관 차원에서는 프로그램에서 제공하는 정량화된 측정 지표와 기준을 활용해 최적의 마이크로데이터 공개 범위를 설정할 수 있다.
안형준 통계청장은 "통계청이 통계자료 개방과 관련한 지침이나 가이드라인 제공을 넘어, 실무에 적용할 수 있는 자동 프로그램을 보급한 것은 이번이 처음"이라며 "정부가 AI 대전환을 통한 세계 3대 AI 강국 도약을 목표로 하고 있고, 이를 위해서는 양질의 데이터인 국가통계를 안전하게 개방할 수 있는 인프라 지원이 반드시 필요하기 때문에 프로그램을 보급하게 됐다"고 밝혔다.
안형준 청장은 "이번 비식별화 프로그램 보급을 계기로 통계청은 최신 정보보호 신기술 연구와 인프라를 확충, 437개 국가통계작성 기관 전체가 보다 많은 데이터를 손쉽고 안전하게 개방할 수 있도록 적극 지원하겠다"고 말했다.
KOSTAT-Did 화면(사진 : 통계청 제공) *재판매 및 DB 금지



